

Provenance Matters: Why Citations Are the Missing Link in Insight-Driven Decisions
by Jake Burghardt

Subscribe to get sharp thinking all about ResearchOps delivered straight to your email inbox. It’s free!

The ResearchOps Review is supported by User Interviews, now part of UserTesting. User Interviews makes it fast, easy, and affordable to recruit participants so you can scale research without sacrificing quality.
On many occasions, I’ve watched product executives sit around a table with their peers and make the case for major initiatives based on research data they happened to remember in the moment. Even if their memory was correct (and that’s a big “if”), and customer research was being applied to great effect, that particular insight couldn’t be verified because it was impossible to find the data that sat behind the insight: there was no traceability. If the author of the research happened to be in the room, they might have been able to point out the insight’s origin and context. But research authors can’t be guaranteed to be in the room every time their research is quoted, or be expected to remember every source. While it’s possible to systematize this capability, most organizations—at least those that aren’t in the scientific or medical fields—haven’t made that investment. As a result, they’re not able to easily check an insight’s source—more formally, a citation—to gain an on-the-spot understanding of its context.
“Context” can mean different things in different studies, initial research uses, and applications of insights over time. For instance, robust ethnographic methods can build thick contextual descriptions of customers’ worlds, while narrow-scoped surveys can maintain the contextual fingerprint of a particular sample and its timing in product development. Even in sparse, agile documentation, carefully chosen wordings can tell a larger story of uncovered needs and possible actions. During a research study, at least when collaboration is ideal, researchers and their stakeholders tend to share stories during meetings, observation sessions, show-and-tells, and via messaging apps. Over time, they’ll build up a shared context that colors every interaction they have about the study. These stories are knowable because they’re grounded in collaboration. But after a study is complete and the researcher and their stakeholders move on, layers of context are easily lost. Maintaining contextual provenance can become a major knowledge management challenge, and an opportunity to build storage, structures, and connections that operationally squeeze value from existing research.
This article outlines how leveraging citations in research repositories can enable more context-rich usage of research insights, how links from plans into repository contents add value for both product decision makers and insight generators (and provide more research value to the organization), and how to effectively operationalize those linkages via citation patterns. I’ll share good, better, and best examples.
Understanding Citations—and Why They Matter
If you’ve read (or written) an academic research paper or book, you’re likely to have come across a formal academic citation. A citation is simply a reference or credit to the original source or sources. In the context of user experience (UX) research, citations are links that a researcher, team, or ResearchOps professional can follow to understand whether and where a particular insight has been applied in product decision-making. Every researcher loves it when decision makers cite the insight—their insight—that informed a particular choice.
Even though generative AI tools are normalizing reference links—deep-research tools like Google’s NotebookLM and Perplexity include citations as standard—the word “citation” can seem just a bit too academic for the product development context. I suggest avoiding the formal citation standards, such as APA, MLA, Chicago, or IEEE, for this type of usage.1 The goal of using citations is to create context between research and product documents; the focus is on making context traceable, not nitpicking or achieving academic perfection. Still, the primary premise of a citation is invaluable in the product context, and for the following reasons.
Enabling a Deeper Dive into the Evidence
While working in ResearchOps knowledge management, I often had to follow up with the authors of roadmap themes, product requirements documents, designs, and other deliverables to learn where a cited customer quote or statistic came from. For some of these queries, the answers were less than convincing, balancing on a cherry-picked snippet of information used to justify an idea already in-flight. Other times, because there was a citation, I could clearly see the insight’s source research. I knew I could drill down into a report or reach out to the researcher to learn more. The ability to gather more context helped me build trust in using traceable evidence to support a choice. But it’s not just about what worked for me personally; citations can help scale trust across a product organization, too.
Improving Research Impact Tracking
Researchers working in technology organizations are often asked to demonstrate the impact of their work. To effectively meet this expectation, many research practitioners find ways to proactively record their influence and results. In a Learners conference talk called “Impact and UX Research: What Is It and How Do We Know We’ve Achieved It?” Victoria Sosik, a senior director of experience research, shared some basic trackable categories of impact, such as prompting future collaborations and influencing product strategy, as well as logging individual wins (or citing them) so they can be compiled and shared in status reporting.
After researchers wrap up their studies, tracking connections between research and planning can get cloudy. Researchers often hope that decision makers will continue to find value in and make use of their research repository beyond an initial project. But even when “old” insights make a difference in current plans (backlogs, specifications, user stories, roadmaps, goals, and designs, etc.), those impacts can be untraceable unless there’s some sort of citation.
Building Context in Research Repositories
I began focusing on research repository design in 2013, while I was a principal researcher at Amazon (eventually transitioning to a ResearchOps role) and when research repository work was at the frontier. The UX research team at the time had generated extensive, in-depth insights that had informed measurable impacts for customers and the business. Even with these immediate wins, researchers’ collected body of past learning still had a lot to offer future initiatives—there was still juice to squeeze from the research fruit. To harvest that research wealth, the team adapted a commonly used, off-the-shelf issue-tracking tool to serve as an insight-level research repository. Over time, adoption of the repository grew across a range of product teams in three divisions.
As adoption increased, I noticed something surprising: decision makers started adding research citations into their own work artifacts, such as product requirements, roadmaps, and strategy documents. References to specific insights appeared in all sorts of deliverables, sometimes created by colleagues whom none of the researchers had met. Notably, citations appeared in product teams’ launch announcements. Some product owners, as part of taking credit for a lift in a key business metric, were citing links to the research insights that motivated and shaped their launch. As a result, researchers were able to connect their earlier work to concrete wins that had taken some time—and many actors—to realize. This was not just a general, conceptual influence. These launch numbers were specific, traceable improvements to a north star key performance indicator (KPI). Because research was cited, the research team was able to tally these metrics across launches to demonstrate collective impact.
When it comes to maintaining (and even building) this kind of citation practice, a research repository is an important lever. While definitions vary widely, I tend to think of research repositories as intentional “places” for research storage, access, and use. A repository doesn’t have to be a purpose-built tool—people use standard-issue workflow tools to build repositories all the time—but it can be. Though the technology is important, it’s the collaborative intention and operations built around it that make a repository effective. Increasingly, those operations can extend into building Retrieval-Augmented Generation (RAG) systems and seeing AI agents (along with humans) as regular repository users, with key requirements around providing structured and machine-legible content via Model Context Protocol (MCP).
To return to the Amazon story, before you rush out and try to replicate it, remember that the experience was just one idea for a research repository, built for a specific time and context. Research repositories are systems, and systems can take on many forms depending on the problem the system is designed to solve. For example, some research organizations need a repository that supports key aspects of the research workflow, such as transcribing video interviews and tagging emergent themes. Other research organizations are focused on building evidence for important user insights across a variety of studies. There are many other possible outcomes, and not every solution will meet every requirement, but whatever your requirements or technology, being thoughtful about how you capture context is key.
Establishing Patterns for Citing Research
It takes effort to locate evidence and reference it—to cite it—and in the midst of the busyness of doing their primary job, decision makers may not prioritize that effort. Even when AI has done the work of creating links to supporting research content, decision makers may not think to preserve those connections. When they do cite research sources, you’ll likely see a lot of variation in approach, for no real reason, and some approaches will be better than others.
Patterns for research citations can tackle some of these issues by clarifying what’s valued and expected and providing standards that people and AI can use to embed clear, consistent, (human- and machine-) legible references. In Chapter 11 of Stop Wasting Research, I wrote about how research teams and internal communities can come together to design citation patterns. I wrote, “Early adopters of your knowledge management tools will develop their own varying approaches for incorporating research-based rationale into their backlogs, roadmaps, goals, designs, specifications, and other planning deliverables. You don’t have to wait for those patterns to emerge—you can develop standards for traceable research citations and encourage their adoption” (page 237). Those “standards for traceable research citations” are what I now call citation patterns. In that chapter, called “Link Research Rationale to Plans,” I identified example patterns with different quantities of cited content, from basic references that include only an informative link to comprehensive excerpts of research that bring the deep dive into the citation itself.
More recently, I’ve realized that the type of information that gets linked to in a citation is a factor that’s worthy of some patterns as well. If you do an audit to review how people are citing research in planning documents in your organization—assuming they exist—you may find that decision makers cite very different types of research content, from a single point of evidence to a whole research report. These existing examples can be a great place to start in building more formalized patterns.
The following three patterns represent a point of view on what good, better, and best research citations might look like in a product decision maker’s—or anyone’s—deliverables. Please keep in mind that this pattern set is not exhaustive. Also, these patterns aren’t foolproof. Decision makers may still cite the wrong insights in their plans. However, these patterns can make the application of research-based rationale more discoverable and assessable, enabling anyone in your organization to more easily evaluate how data either supports or contradicts product decisions.
Good (Pattern 1): Linking to Research Evidence
The first pattern is about citing snippets of research evidence as a rationale for a decision, and providing a link to where the evidence is stored. For example, I once reviewed a designer’s PowerPoint slides that linked to a research highlight reel stored in the project’s folders in a shared drive, which was acting as a basic centralized research repository. It was the kind of video evidence that makes a strong point and could be used to justify a design direction. But to understand the video’s context, and the research of which it was a part, I had to navigate around a folder structure, which initially felt like an uninformative list of file names, to find the study name and plan (see Figure 1). It took some poking around to learn anything more about the video, and the context from which it came.
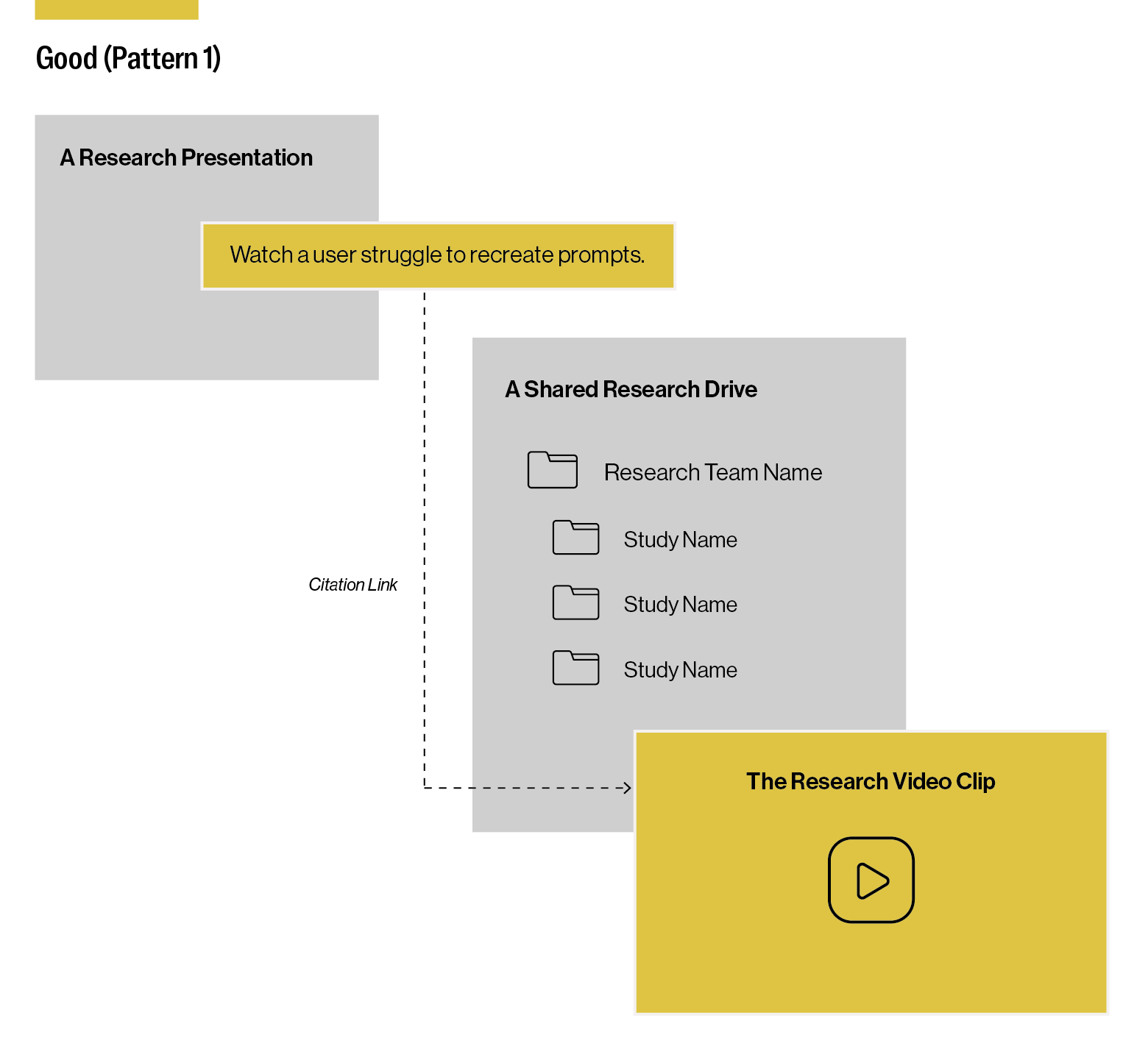
Alternatively, this citation pattern may deep-link to a specialized analysis tool that’s serving a dual role as a research repository. If the viewer has permission to access the application and is invested in exploring, they may be able to see related themes, analyses, and data in the project.
Pattern 1 pros:
The link destination may provide contextual clues about who created the evidence and the nature of the study (or it may be fairly opaque).
Following the link may enable some contextual investigation to learn more.
Pattern 1 cons:
The decision maker needs to know where to look for evidence and browse content until they find relevant support for their rationale.
Limited context may make it difficult to tell whether cited evidence has been cherry-picked to support a choice or is the result of a well-designed research process.
Depending on the repository tool used to store evidence, the reviewer may have few options to navigate and find more information.
Additional evidence for the same learning across studies isn’t included in the link destination, reducing the clarity and persuasiveness of the research.
Research governance policies may lead to the deletion of evidence, leading to dead links in citations.
This pattern is not ideal, but it’s better than nothing. Using consistent descriptive metadata can increase the legibility of individual pieces of evidence. A colleague once called descriptive metadata the “nutrition facts” of a research asset. This descriptive information can also help AI agents choose which information to pull into their context window when executing a task.
There’s value in coming together as a community of research repository contributors to define a standardized set of metadata. A published standard like the ResearchOps Community’s "Minimum Viable Taxonomy Level 1“2 by Ian Hamilton, Emily DiLeo, India Anderson, Mark McElhaw and Annette Boyer (on behalf of the entire Research Repositories Program Team) can act as a starting point for discussion.
Better (Pattern 2): Linking to Insights in a Research Report
This second pattern is about a headline that cites rationale from an individual research report and links to its destination in a research repository. That linked research report can provide rich context for the specific finding in the citation. Linked reports can also encourage additional learning from other areas of the same study. For example, I’ve been excited to see citations linked to research reports in product leaders’ requirements documents. The citation text alone provided strong contextual cues, and the linked document provided many more (see Figure 2).
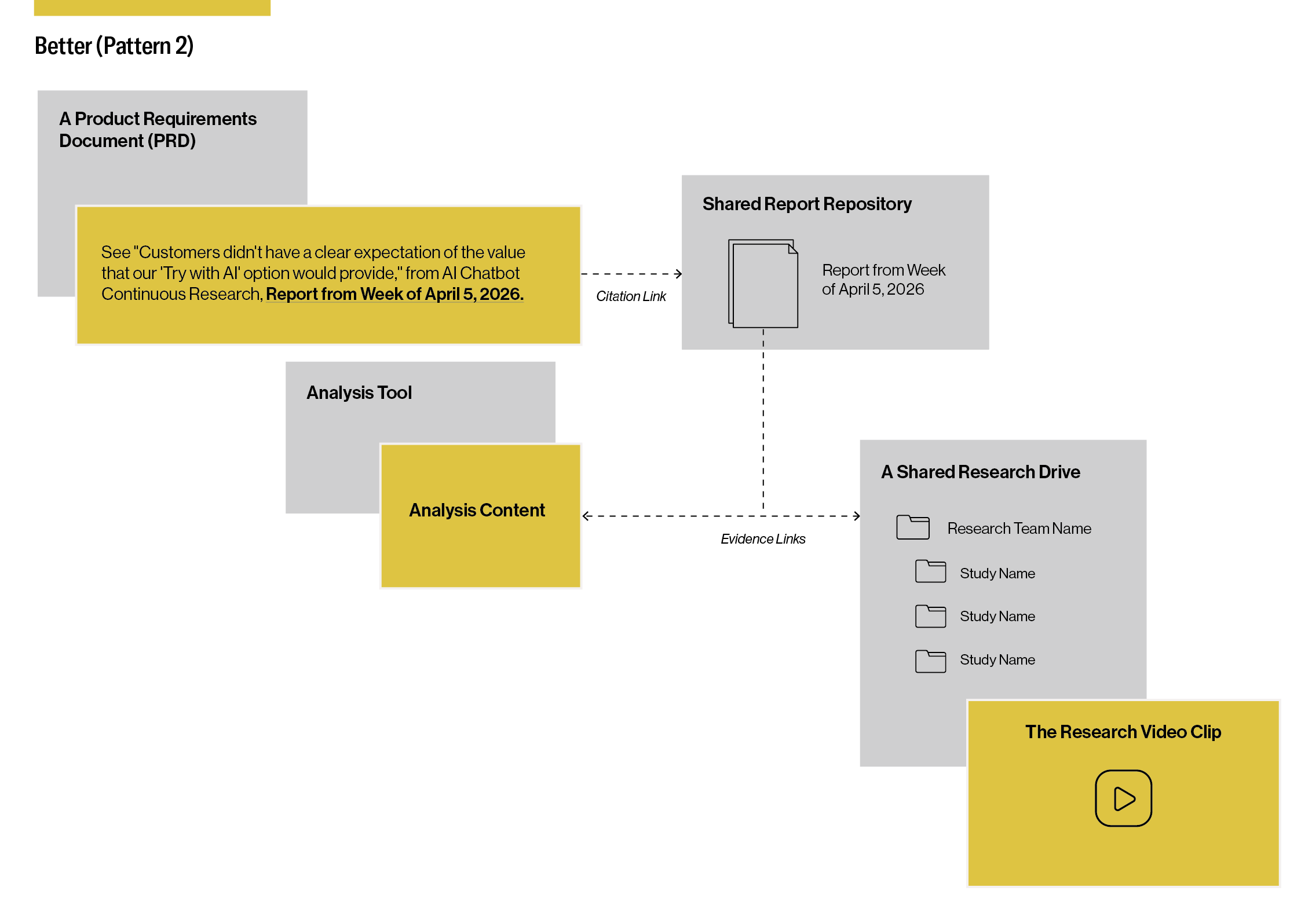
Pattern 2 pros:
A named study link gives contextual clues as to who created the cited evidence and the nature of the study.
Research language is used in the citation itself, showcasing the researcher author’s interpretative labor and intentional framing.
Linked reports can provide rich contextual information, depending on the depth of the documentation.
Linked reports may themselves include links to specific evidence, similar to Pattern 1.
Researchers typically create reports, so the effort of contributing those outputs to a research library is not extensive (and can potentially be supported with some automation).
Pattern 2 cons:
A decision maker using this pattern needs to be aware of the research repository, have access to the tool, and have knowledge of desired citation standards.
Depending on the repository tool being used, you may not be able to use anchor links (links that link straight to a particular location in a document). If a link doesn’t take a reader to the right place on the page, understanding and assessing cited rationale may require extra reading and cognitive overhead, which might be rewarded with additional understanding but risks a loss of attention or patience—or both.
Additional evidence for the same learning across studies isn’t included in the link destination. If the same insight was found ten other times, an individual report typically won’t incorporate this extended evidence.
Best (Pattern 3): Link to an Insight Summary
This third pattern is about a defined insight headline that links to a particular pre-prepared insight summary containing evidence excerpted from across reports. These insight summaries act as a one-stop shop for research about a single insight. Given that insight summaries take dedicated effort to prepare (a task that may be supported by generative AI), researchers may only prepare them for top, high-priority, underutilized insights that they want to see more action towards.
I’ve seen CEO-level initiative planning documents, prepared by product managers, that contain links to insight summaries to justify particular backlog items. While reviewing the planning documents, the titles of these insight summaries could be taken as standalone statements about user needs (see Figure 3). Following a citation link leads to a rich inventory of related evidence from studies to date. The specificity of these citations enables the tracking of progress toward individual customer problems in complex topic areas.
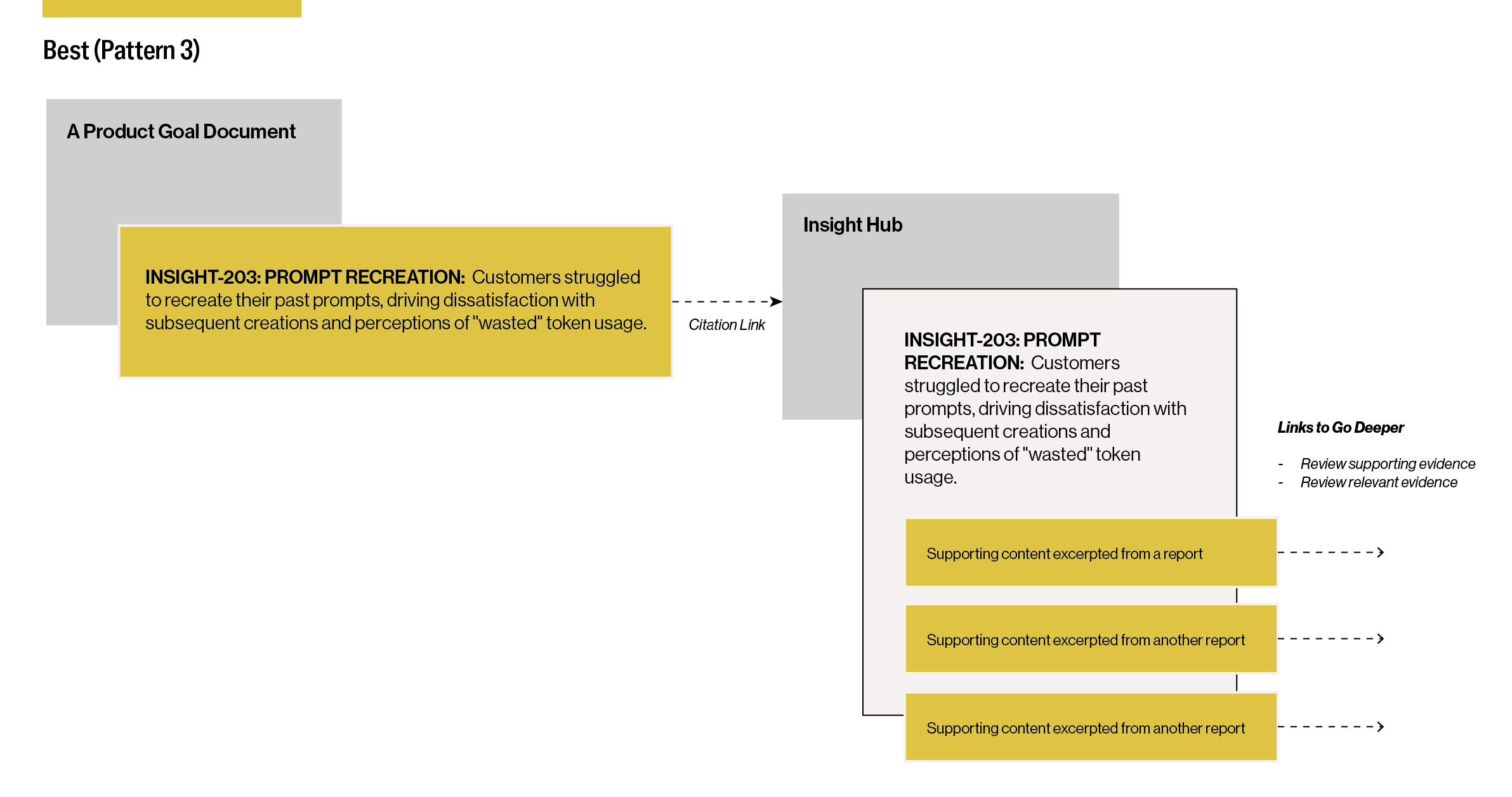
Insight summaries can be implemented as simple documents in a common productivity tool, or as something more elaborate in specialized repository software. Similar to documenting and updating “nutrition facts” (or descriptive metadata), repository contributors can come together to create shared standards for how they document and update insight summaries.
Pattern 3 pros:
A clear identifier provides a branded clue that this research comes from a particular community and is stored in a specific, trusted research repository.
A research-authored insight title provides a core user observation and business implication, showcasing researchers’ collective interpretative labor and precisely framing next steps.
Insight seekers can dive into and be persuaded by a single “place” for a specific insight, reviewing all supporting (and even contradicting) evidence. Insight summaries preserve context from excerpted studies while also building new meaning across studies.
Similar to Pattern 2, linked reports within an insight summary provide rich contextual information, depending on the depth of the documentation. Insight summaries may allow for deeper inspection of evidence, containing links similar to Pattern 1.
Every time an insight summary has an impact, all of the researchers whose work is represented in the summary can claim credit. (This can be a strong motivator for researchers to take part in authoring summaries.)
Pattern 3 cons:
As with Pattern 2, a decision maker using this pattern needs to be aware of the research repository, have access to the tool (or have received a list of “their” relevant insights from the collected catalog), and have knowledge of desired citation standards.
Researchers will need to put in extra effort beyond typical study processes to create insight summaries for top insights. Generative AI may be useful in this process, answering questions about standards, identifying potential evidence from across studies to inform an insight summary, and helping to format content within a summary.
Preservation Through Positive Feedback Loops
Similar to the value of surfacing references in a generative AI chat summary, displaying links to relevant research in planning deliverables is the “double click” that expands into a clearer, more trustworthy picture. As some teams explore how entire UX research repositories could become contextual inputs to AI agents, it’s tempting to think that these kinds of citations are old news—like knowing where research is being applied is somehow becoming an antiquated idea. It’s not. Important product decisions will always benefit from clear rationale, and that basic need is something that research operations can look for new ways to enable. If anything, new technology may provide novel ways of identifying and supporting citations.3
As with many aspects of product development, no single role or individual owns successful research citation in product decision-making. With this in mind, insight-driven leaders and repository contributors can spotlight the behaviors they want to see become more prevalent. I’ve found that visibly celebrating winning product launches and experiments that cite research can propagate the idea of citation as a best practice worthy of adoption.
Even if your organization has a richly populated research repository, you’ll never see complete adoption of research citations in key product decisions. But turning up the frequency of citation can infuse researchers’ existing learning into more strategic planning decisions—the type that executive leaders tune into. Increasing citation frequency, in turn, can motivate researchers to be more invested in contributing to their shared research repository, building the depth of connected learning. As positive feedback loops continue to cycle, research impact broadens, and outcomes improve for customers and the business. All from keeping research learning alive, preserving its context, connecting it into new, meaningful choices—from headline to deep dive.

The ResearchOps Review is made possible by User Interviews, now part of UserTesting. With a vast participant network, precise matching, and fraud prevention, User Interviews can reliably fill any research study. Source, screen, track and pay participants, then move seamlessly from data collection to deep analysis, all in one place. → Learn more about User Interviews for ResearchOps.
"Citation Styles: APA, MLA, Chicago, Turabian, IEEE: Overview Need Help with Formatting Citations? Use This Brief Guide to Five Major Styles." University of Pittsburgh Library System. University of Pittsburgh, February 18, 2026. https://pitt.libguides.com/citationhelp.
DiLeo, Emily. "Introducing the Minimum Viable Taxonomy Level 1." Medium. ResearchOps Community, November 1, 2022. https://medium.com/researchops-community/introducing-the-minimum-viable-taxonomy-level-1-63d13589fdcb.
Burghardt, Jake. "AI Agent Ideas in Research Knowledge Management: Some GenAI Use Cases to Increase Usage of Customer Insights in Product Development." Medium. November 6, 2025. https://medium.com/integrating-research/ai-agent-ideas-in-research-knowledge-management-cca2f92d2dd0.
 | A guest post by
|
Good stuff! I do wonder where recommendations fit into this? My take is that insights aren’t sufficient that we need to be working with recommendations and tracking those and showing what I call the “chain of evidence” back to insights to results and to data. But I love this article!